基于 CPG+PD+SAC残差强化学习的人形机器人行走仿真
1. 项目概述
1.1 项目简介
本项目基于 MuJoCo 物理仿真平台,搭建了一套 CPG周期步态生成 + IMU姿态PID稳定 + 足底力自适应PD控制 + SAC残差强化学习微调 的分层人形机器人控制系统。区别于传统纯规则控制方案,本项目以手工稳定控制为基线,引入残差强化学习,让SAC强化学习模型仅输出微小关节补偿增量,修正传统CPG步态的抖动、偏移、稳定性不足问题。
项目支持 Windows 键盘实时交互、ROS /cmd_vel 话题远程控制、多步态模式切换、SAC 模型在线加载微调、课程式强化学习训练、仿真域随机化,实现了从纯规则稳定行走到 AI 智能优化步态的完整闭环,兼具工程稳定性与算法研究价值。
整体系统可直接运行、可复现、可拓展,完美适配人形机器人规则控制基线搭建、强化学习步态优化、Sim2Real 迁移学习等研究与工程开发场景。
1.2 项目整体流程
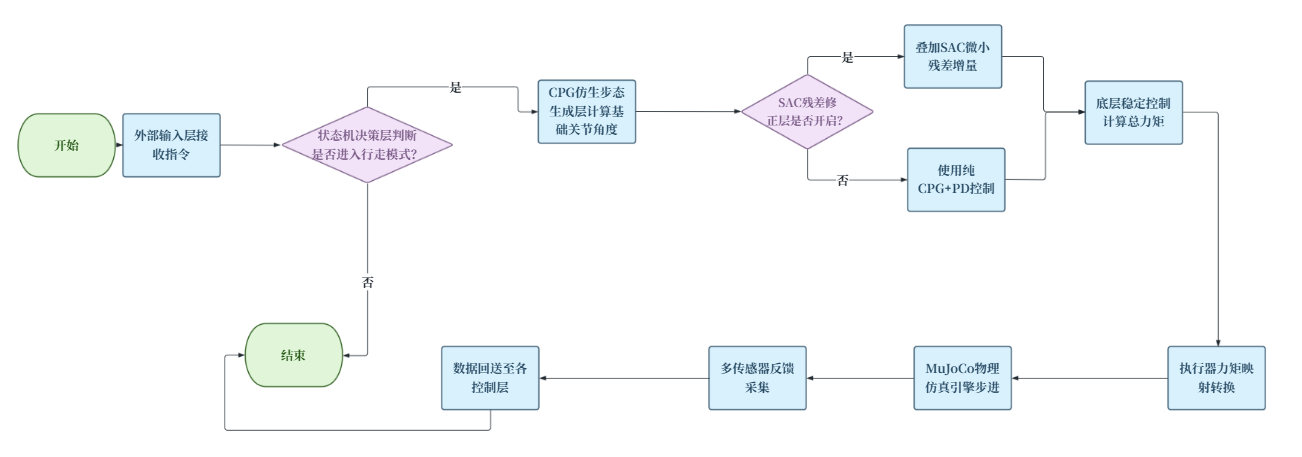
图1 项目整体运行流程图
本项目采用分层控制架构,其中底层由基于模型的CPG步态生成与PID/PD姿态及关节控制保障机器人基础行走稳定性,该控制器不依赖学习,完全依据物理模型与确定性参数,能够在任意状态下输出保守的控制信号,确保机器人即使在学习模块失效或未激活时仍能稳定行走、转向及启停,从而提供明确的安全下界。上层则引入SAC强化学习模型,该模型不直接生成主控制指令,而是学习输出一个幅值受限的残差动作信号,用以修正底层规则控制器的输出缺陷,例如抑制步态振荡、提升速度跟踪精度以及增强对外部扰动的鲁棒性。
1.3 项目组成
| 模块 | 类/函数 | 核心功能 |
|---|---|---|
| 双输入交互模块 | ROSCmdVelHandler、KeyboardInputHandler |
多线程异步监听,支持键盘/ROS双通道控制,无ROS自动降级 |
| 状态机调度模块 | HumanoidStabilizer.state_map |
STAND/PREPARE/WALK/STOP/EMERGENCY五状态无缝切换 |
| 基础步态生成模块 | CPGOscillator |
Hopf耦合振荡器,生成左右腿反相周期步态,自适应速度/转向参数 |
| 底层稳定控制模块 | _calculate_stabilizing_torques |
躯干姿态PID+关节PD自适应+足底力刚度补偿+积分抗漂移 |
| 强化学习环境模块 | HumanoidGaitEnv |
Gym标准训练环境,37维观测、14维残差动作、域随机化、多目标奖励 |
| 课程训练模块 | CurriculumWrapper、CurriculumCallback |
三阶段课程学习,渐进式训练站立→低速行走→全速稳定行走 |
| 模型训练与优化 | SAC、GradientClipCallback |
SAC柔性策略训练+梯度裁剪,防止训练梯度爆炸 |
| 执行器映射模块 | _torques_to_ctrl |
关节力矩→MuJoCo执行器控制量精准转换,适配gear/ctrlrange约束 |
| 仿真主循环 | simulate_stable_standing |
可视化仿真、物理步进、实时控制闭环、线程资源管理 |
本项目的核心价值在于:形成完整的人形机器人规则控制与强化学习残差优化的混合闭环架构,而非单一功能脚本。
1.4 核心技术特点
| 核心特点 | 详细说明 |
|---|---|
| 双层控制架构 | 底层用 CPG 和 PD 控制保证机器人基本不摔倒,上层用 SAC 强化学习输出小的调整量,改善行走效果 |
| 耦合CPG步态 | 使用 Hopf 振荡器让左右腿交替迈步,相位差固定为 π,可以根据速度、转向和脚底接触情况自动调整参数 |
| 自适应稳定控制 | 根据脚底受力大小改变关节刚度,受力大时刚度增加,受力小时刚度减小。同时用姿态 PID 抑制身体倾斜,加入跌倒保护 |
| 残差强化学习 | SAC 模型只输出 ±0.08 弧度以内的关节角度增量,不改动原有 CPG 步态的主要形态,训练收敛比较快,也比较稳定 |
| 课程式训练 | 训练分成三个阶段:先练站立,再练慢走,最后练正常速度行走。这样可以降低一开始的训练难度 |
| 域随机化增强 | 训练时随机改变地面摩擦、关节阻尼、电机增益,还会偶尔推一下机器人,让学出来的策略适应更多不同情况 |
| 双通道交互 | 支持两种控制方式:用键盘直接控制,或者接收 ROS 的 /cmd_vel 消息控制,方便调试和集成 |
| 工程化鲁棒机制 | 加入了一些保护措施:启动时力矩慢慢增加、IMU 数据滤波、摔倒后冷却一段时间、力矩限幅、状态机防止误触发 |
1.5 运行模式说明
- 仿真交互模式:注释
train_sac(),启动可视化仿真,支持键盘 / ROS 控制、加载 AI 步态 - RL 训练模式:开启
train_sac(),自动执行 1000 万步课程式 SAC 训练,保存模型权重
ROS 可选接入
发布标准机器人速度指令,机器人自动响应行走、转向、站立:
rostopic pub /cmd_vel geometry_msgs/Twist "{linear: {x: 0.22}, angular: {z: 0.1}}" -r 10
1.6 项目核心目标
- 搭建高稳定性 CPG+PD 规则控制基线,实现人形机器人稳定站立、多模式行走、转向、启停
- 实现 SAC 残差强化学习优化,解决传统手工调参步态抖动、速度跟踪差、抗扰动弱问题
- 构建标准化 Gym 训练环境,支持课程学习、域随机化、多目标奖励优化
- 实现多平台交互兼容,无 ROS 可独立运行,有 ROS 可接入机器人自动驾驶框架
2. 项目背景与问题定义
2.1 项目背景
人形机器人属于高自由度、强非线性、欠驱动系统,稳定平衡与动态行走是运动控制的核心难点。 传统纯手工调参的 CPG、PD 控制高度依赖工程师经验,存在步态僵硬、抗扰动差、速度跟踪精度低、无法自适应环境等问题。 而纯端到端强化学习训练存在训练难收敛、容易崩溃、无基础兜底、安全性差的问题。因此本项目采用规则控制为基底,强化学习做残差微调的创新方案,结合两者优势,既保证基础稳定性,又具备智能优化能力。
2.2 现存痛点
- 纯手工 CPG 步态参数固定,无法自适应速度、转向、足底状态变化
- 传统 PD 控制刚度固定,支撑相与摆动相特性无法自适应,步态僵硬易抖动
- MuJoCo 关节索引、执行器力矩映射易错,极易导致控制发散、机器人摔倒
- 开局仿真接触未建立,机器人普遍存在开局秒摔问题
- 纯 RL 训练无兜底机制,训练崩溃、步态畸形、无法稳定复现
- 缺乏标准化观测、奖励、课程训练体系,无法完成高效迭代优化
2.3 项目建设目标
- 搭建一个基于 CPG 和 PD 控制的人形机器人行走基线,解决开局容易摔倒和行走过程中抖动的问题
- 设计一个残差式 SAC 强化学习框架,让模型只输出较小的关节调整量,不影响原有步态的基本稳定性
- 建立一个三阶段的课程学习流程,让机器人从站立开始,逐步学会慢走,最后达到正常速度行走
- 实现足底力自适应调节关节刚度、姿态 PID 抑制倾斜漂移、跌倒保护等工程机制
- 完成键盘控制和 ROS 话题控制两种交互方式,实现可以实时调控的人形步态系统
3. 核心技术栈与理论基础
3.1 核心技术栈
| 技术类别 | 具体选型 | 功能说明 |
|---|---|---|
| 物理仿真 | MuJoCo 2.3+ | 高精度刚体动力学、接触力计算、实时仿真步进 |
| 数值计算 | NumPy | 滤波、矩阵运算、参数平滑、限幅处理 |
| 强化学习框架 | Stable-Baselines3 (SAC) | 柔性策略梯度强化学习,适合连续动作步态优化 |
| 训练环境 | Gymnasium | 标准化 RL 交互环境,适配主流训练算法 |
| 深度学习 | PyTorch | 策略网络训练、梯度更新、参数优化 |
| 交互通信 | 键盘线程 / ROS | 本地调试 + 机器人远程控制双模式 |
| 开发语言 | Python 3.8+ | 快速迭代、算法调试、仿真控制 |
3.2 仿真层:MuJoCo 物理引擎
MuJoCo 提供高精度连续动力学求解、刚体接触碰撞、多自由度关节动力学计算,是机器人仿真控制的工业级引擎。本项目基于 MuJoCo 实现: - 21 自由度人形机器人全身动力学仿真 - 足底接触力、机身姿态角速度、重心高度实时反馈 - 自定义外力扰动、关节阻尼、摩擦系数域随机化 - 可视化实时仿真、视角自定义、仿真步进精准控制
3.3 系统状态机控制
项目设计五状态有限状态机,实现机器人行为精准调度,杜绝状态抖动与误触发:
| 状态 | 触发场景 | 核心行为 |
|---|---|---|
| STAND 站立 | 初始化、复位、停止行走、跌倒恢复 | CPG复位、锁定稳定站姿、清零行走参数 |
| PREPARE 预备 | 从站立切换行走瞬间 | 0.8s平滑屈膝过渡,避免起步冲击摔倒 |
| WALK 行走 | 预备阶段结束、接收行走指令 | CPG生成周期步态+重心自适应横移+RL残差修正 |
| STOP 停止 | 接收停止指令、低速趋近静止 | 关节目标指数衰减,平滑减速回站姿 |
| EMERGENCY 紧急保护 | 机身倾角过大、重心异常 | 清零所有力矩,强制停机保护 |
3.4 核心控制算法理论
3.4.1 Hopf CPG 耦合振荡器
采用经典 Van der Pol/Hopf 耦合振荡器,生成仿生节律步态,左右腿固定 π 相位差,天然实现交替迈步:
系统根据行走速度、转向角度、足底接触状态动态自适应频率、振幅、耦合强度,支持慢走、正常、小跑、原地踏步四种预设步态模式。同时加入平滑插值机制,杜绝参数突变导致的步态抖动。
3.4.2 足底力自适应 PD 控制
传统固定 PD 刚度无法适配支撑/摆动状态,本项目根据左右足底实时接触力动态修正关节 KP/KD:
支撑相受力大 → 刚度提升,保证行走稳定;摆动相受力小 → 刚度降低,动作柔顺自然,大幅降低足底冲击与机身抖动。
3.4.3 躯干姿态 PID 稳定控制
基于虚拟 IMU 解算机身欧拉角与角速度,对 Roll/Pitch 轴采用 PID 控制抑制倾斜漂移,Yaw 轴采用 PD 控制保证转向稳定,积分项限幅杜绝积分饱和:
输出矫正力矩叠加至腰部关节,实现行走过程中机身始终保持直立平衡。
3.4.4 残差 SAC 强化学习机制
区别于传统 RL 直接输出全身关节角度,本项目采用残差微调架构: - 规则控制器输出基础稳定步态(兜底保障) - SAC 智能体输出 ±0.08 范围内微小关节增量(优化修正) - 最终关节目标 = CPG 基础目标 + RL 残差增量
优势:训练不崩溃、收敛速度快、保留原生稳定特性、AI 仅优化细节抖动与跟踪误差。
3.4.5 标准化 RL 观测与奖励设计
- 37 维观测空间:机身姿态欧拉角、机身角速度、左右足底压力、重心高度、14 维腿部/腰部关节角度、上一步 RL 动作
- 14 维连续动作空间:髋、膝、踝、腰部残差修正量
- 多目标奖励函数:直立姿态奖励、前进速度跟踪奖励、侧向偏移惩罚、姿态角速度惩罚、足底受力均衡奖励、动作能耗惩罚、重心高度约束奖励
3.4.6 课程式渐进训练
- 阶段 0:纯站立训练,学习机身平衡稳定
- 阶段 1:低速小步行走,学习基础迈步节律
- 阶段 2:目标全速行走,优化速度跟踪与步态平顺性
每 3 万步自动升级训练阶段,循序渐进,彻底解决 RL 训练难收敛问题。
3.5 关键工程化核心机制
3.5.1 精准力矩-执行器映射
针对 MuJoCo 执行器 gear 传动比、ctrlrange 范围约束,实现力矩精准转换,解决控制无效、力矩饱和问题:根据关节执行器参数计算最大允许力矩,限幅后转换为仿真可识别的控制量,保证所有关节驱动力有效输出。
3.5.2 开局软启动与落地支撑
仿真初始 7 秒软启动,力矩系数从 0 渐变至 1.0,同时施加机身辅助支撑力,平稳度过接触未建立的不稳定阶段,彻底解决开局秒摔问题。
3.5.3 跌倒检测与冷却锁
通过重心高度、机身倾角判定跌倒状态,自动复位站姿并设置 2 秒冷却窗口,禁止短时间内重复进入行走状态,杜绝连续摔倒震荡。
3.5.4 仿真域随机化
训练过程随机化地面摩擦、关节阻尼、执行器传动增益、外部侧向扰动,提升策略鲁棒性与泛化能力,为后续 Sim2Real 迁移奠定基础。
4. 系统整体架构
本系统采用五层分层架构:
- 输入层:键盘/ROS 双线程异步指令输入
- 决策层:有限状态机调度行走、站立、停止、紧急保护
- 步态生成层:CPG 振荡器生成基础仿生行走节律
- 控制优化层:PID 姿态稳定 + 自适应 PD 关节控制 + SAC 残差 AI 微调
- 仿真反馈层:MuJoCo 物理步进 + 传感器数据回传闭环
规则控制保证下限稳定性,强化学习突破上限性能,实现 1+1>2 的控制效果。
5. 系统核心优化点
5.1 双线程异步交互优化
将键盘监听、ROS 话题接收独立为守护线程,与仿真主循环解耦,不占用仿真算力,输入响应实时、无卡顿,同时兼容有无 ROS 两种环境,适配 Windows/Ubuntu 多平台。
# 键盘监听线程
def keyboard_listener():
global cmd_linear, cmd_angular
while True:
key = input_thread_getchar() # 非阻塞获取按键
if key == 'w': cmd_linear = 0.2
elif key == 's': cmd_linear = -0.1
# ... 其他按键处理
threading.Thread(target=keyboard_listener, daemon=True).start()
# ROS 订阅线程(若可用)
if ros_available:
rospy.Subscriber('/cmd_vel', Twist, callback=ros_cmd_callback)
5.2 精准关节地址映射
摒弃传统固定切片取值方式,通过关节名称匹配 MuJoCo 原生地址索引,彻底解决模型修改后 qpos/qvel 索引错位、控制发散问题,代码通用性极强。
# 建立关节名称到索引的映射
self.joint_name2id = {}
for i in range(model.njnt):
name = model.joint_names[i].decode()
self.joint_name2id[name] = i
# 获取特定关节的位置和速度
hip_id = self.joint_name2id['right_hip_x']
qpos_hip = data.qpos[hip_id]
5.3 四模式自适应步态
内置 SLOW/NORMAL/TROT/STEP_IN_PLACE 四种步态参数,可一键切换,每种步态独立配置频率、振幅、速度增益、重心偏移参数,适配不同行走场景。
# 步态参数预设字典
gait_config = {
'SLOW': {
'freq': 0.8, # 步态频率 (Hz)
'amp': 0.3, # 摆动幅度 (rad)
'swing_gain': 0.6, # 迈步增益
'com_shift': 0.02, # 重心横向偏移 (m)
'arm_amp': 0.2 # 手臂摆动幅度
},
'NORMAL': {
'freq': 1.2, 'amp': 0.45, 'swing_gain': 1.0, 'com_shift': 0.03, 'arm_amp': 0.3
},
'TROT': {
'freq': 1.8, 'amp': 0.5, 'swing_gain': 1.2, 'com_shift': 0.04, 'arm_amp': 0.35
},
'STEP_IN_PLACE': {
'freq': 0.9, 'amp': 0.2, 'swing_gain': 0.0, 'com_shift': 0.0, 'arm_amp': 0.1
}
}
# 切换步态模式
def set_gait_mode(self, mode: str):
if mode in gait_config:
self.current_gait = mode
params = gait_config[mode]
self.cpg.set_frequency(params['freq'])
self.cpg.set_amplitude(params['amp'])
self.swing_gain = params['swing_gain']
self.com_shift_target = params['com_shift']
self.arm_amp = params['arm_amp']
5.4 重心动态平衡优化
根据左右足底压力差实时修正髋关节横向偏移,行走过程中自动向支撑腿重心偏移,抵消迈步带来的机身倾斜,大幅提升动态行走稳定性。
# 获取左右足底垂向接触力(单位:N)
left_force = self.sensor_data.get('left_foot_force_z', 0.0)
right_force = self.sensor_data.get('right_foot_force_z', 0.0)
# 计算压力差,正值表示左脚受力更大
force_diff = left_force - right_force
# 根据压力差计算髋关节横向偏移量(单位:rad)
# k_balance 为平衡增益系数,max_offset 为最大允许偏移
hip_lateral_offset = self.k_balance * force_diff
hip_lateral_offset = np.clip(hip_lateral_offset, -self.max_hip_offset, self.max_hip_offset)
# 将偏移叠加到髋关节横向目标角度上(base_lateral 为中立位置)
self.target_qpos['hip_lateral'] = self.base_lateral + hip_lateral_offset
5.5 手臂协同摆动优化
手臂与腿部步态反向协同摆动,抵消行走过程机身扭转力矩,减少 yaw 轴偏移,让步态更自然、平稳。
# 获取当前腿部步态相位(例如右腿相位)
leg_phase = self.cpg.get_phase('right_leg')
# 手臂摆动相位与对应腿相反(相差 π 弧度)
arm_phase = leg_phase + np.pi
# 计算手臂摆动角度,arm_amp 为摆动幅度
arm_angle = self.arm_amp * np.sin(arm_phase)
# 左肩和右肩反向摆动,进一步抵消扭转
self.target_qpos['left_shoulder_x'] = arm_angle
self.target_qpos['right_shoulder_x'] = -arm_angle
# 肘关节保持固定弯曲角度,避免上抬
self.target_qpos['left_elbow'] = self.elbow_bend
self.target_qpos['right_elbow'] = self.elbow_bend
5.6 SAC 梯度裁剪优化
自定义梯度裁剪回调,限制训练梯度范围,杜绝梯度爆炸,提升训练稳定性与收敛效率。
from stable_baselines3.common.callbacks import BaseCallback
import torch
class GradientClipCallback(BaseCallback):
def __init__(self, clip_val=0.5, verbose=0):
super().__init__(verbose)
self.clip_val = clip_val
def on_step(self):
# 获取策略网络(包括Actor和Critic)的所有参数
policy = self.model.policy
# 对Actor和Critic的梯度进行裁剪
torch.nn.utils.clip_grad_norm_(policy.actor.parameters(), self.clip_val)
torch.nn.utils.clip_grad_norm_(policy.critic.parameters(), self.clip_val)
# 如果有目标网络,也可裁剪(一般不需要)
return True
# 训练时使用回调
model = SAC('MlpPolicy', env, verbose=1)
model.learn(total_timesteps=100000, callback=GradientClipCallback(clip_val=0.5))
5.7 低通滤波降噪
对 IMU 姿态角、机身角速度做一阶低通滤波,滤除仿真高频噪声,避免控制高频抖动。
class LowPassFilter:
def __init__(self, alpha=0.2):
"""
一阶低通滤波器
:param alpha: 滤波系数,取值范围 (0,1),alpha 越大响应越快,滤波效果越弱
"""
self.alpha = alpha
self.last_val = None
def filter(self, new_val):
if self.last_val is None:
self.last_val = new_val
else:
self.last_val = self.alpha * new_val + (1 - self.alpha) * self.last_val
return self.last_val
# 创建各个传感器的滤波器
roll_filter = LowPassFilter(alpha=0.3)
pitch_filter = LowPassFilter(alpha=0.3)
yaw_rate_filter = LowPassFilter(alpha=0.25)
# 仿真循环中读取原始数据并进行滤波
raw_roll = data.sensor('imu').data[0]
raw_pitch = data.sensor('imu').data[1]
raw_yaw_rate = data.sensor('gyro').data[2]
filtered_roll = roll_filter.filter(raw_roll)
filtered_pitch = pitch_filter.filter(raw_pitch)
filtered_yaw_rate = yaw_rate_filter.filter(raw_yaw_rate)
6. 核心技术难点与解决方案
6.1 难点:躯干后仰弯折与手臂上抬失衡
问题:行走过程中出现两个相互关联的姿态问题。一是躯干自发后仰,腹部多节关节(abdomen_x)弯折变形,如图2所示。
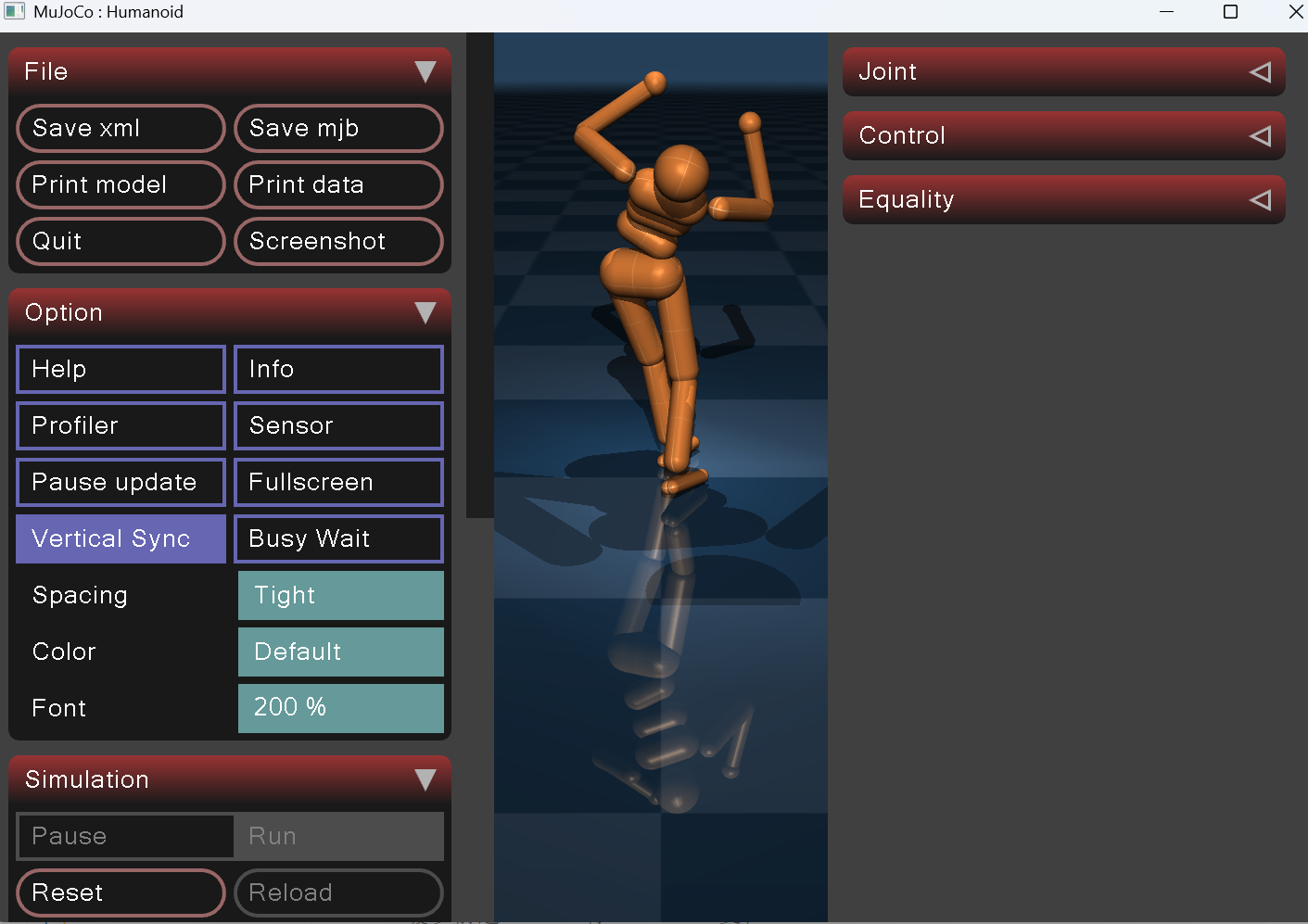
图2 行走中躯干后仰弯折
原因:因为CPG步态中的动态俯仰补偿逻辑不合理,加上腰部PD刚度过低,所以导致迈步时身体向后弯曲。二是手臂不受控制地大幅上抬,摆动幅度过大,反向拉扯上身进一步加剧后仰倾倒,是肩部关节基准坐标偏高且手臂CPG摆动幅值过大导致的。
解决:针对躯干问题,将 abdomen_x 俯仰基准值锁定为0,移除所有速度或误差驱动的前倾后仰动态增量;同时大幅提高腰部abdomen三轴PD刚度,对躯干形态进行刚性约束;并在姿态控制环中叠加俯仰积分纠偏力矩,主动拉回竖直姿态,效果如图2所示。针对手臂问题,强制下沉肩部静态基准偏移量,大幅压缩手臂左右摆动幅度;设置肘部固定下垂弯曲角度,提高手臂关节PD增益以限制抬升自由度,并彻底隔绝步态信号对手臂抬升方向的驱动。
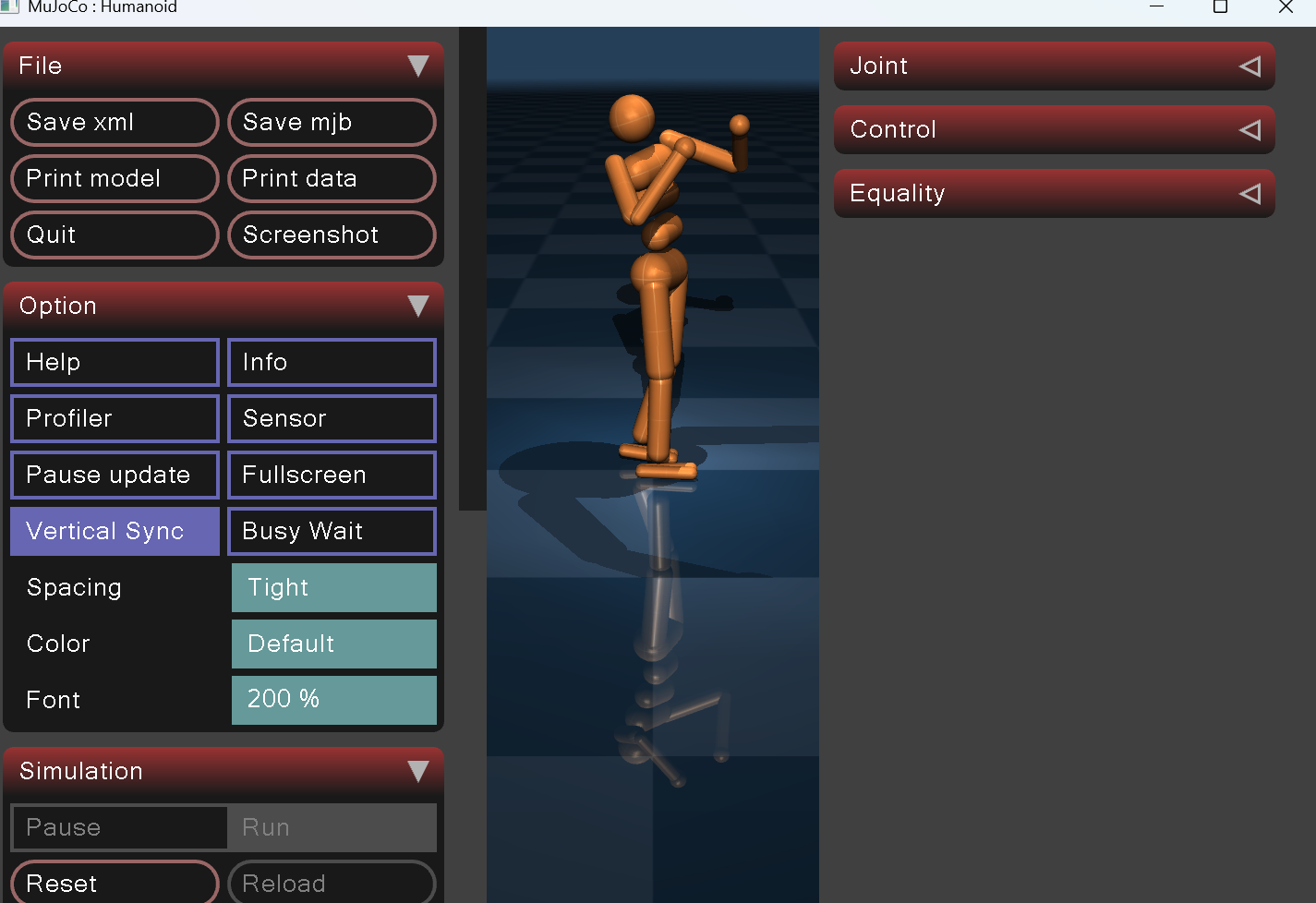
图2 修正后躯干基本保持竖直
6.2 难点2:SAC残差RL扰动破坏基础稳定姿态
问题:旧版SAC动作输出幅值偏大,AI探索时会修改躯干、手臂目标角度,覆盖CPG稳定基准姿态,造成弯腰抬臂畸形动作。
原因:在残差强化学习框架中,SAC智能体的动作输出直接叠加到CPG生成的基础关节目标上。旧版实现中,动作空间未针对不同关节类型进行差异化约束,躯干和手臂关节的残差范围与腿部关节一致(约±0.2~0.3 rad)。由于训练初期策略探索随机性强,AI频繁输出较大的躯干弯曲量和手臂抬升量,而这些关节在CPG原生步态中本应保持固定或极小变化。较大的残差覆盖了CPG的稳定基准,导致原本直立的躯干发生弯腰、手臂上抬等畸形姿态,进而破坏整体平衡,也使得奖励信号混乱,训练难以收敛。
解决:极限压缩RL动作缩放系数与幅值上下限,限制仅能微调腿部关节;躯干、上身关节的RL增量施加严格硬截断约束;训练奖励函数大幅加大俯仰、抬臂姿态惩罚项,引导AI不破坏上身形态。
6.3 难点3:步伐幅度过大、频率过快导致机身晃动、稳定性差
问题:CPG固有振幅、频率参数偏高,大步快节奏迈步造成重心剧烈上下/前后波动,机身摇晃易倾倒,如图4所示:
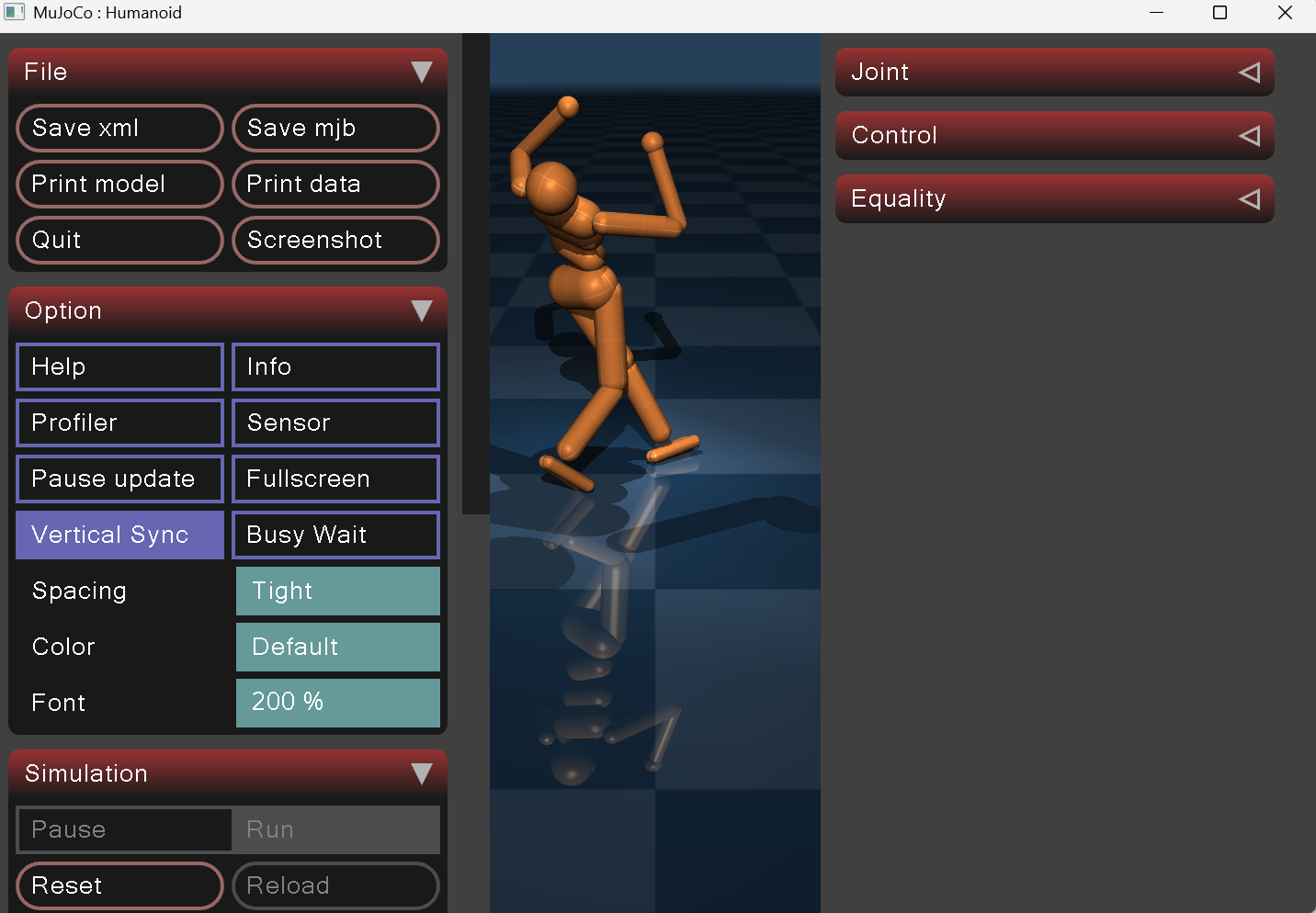
图4 大步快节奏迈步导致机身摇晃
原因:原始CPG参数为了追求较快的行走速度,默认设置了较大的振幅和频率。振幅过大使得迈步时脚离地过高,髋、膝、踝关节角度变化剧烈,带动质心大幅上下起伏;频率过高则压缩了支撑相的时间,左右腿切换时重心转移来不及平滑过渡。两者叠加,机器人在每一步的落地冲击和起身过程中都会产生明显的前后俯仰和侧向晃动,尤其在速度指令变化时步态无法及时适应,稳定性严重下降。
解决:分档位步态配置,默认启用小幅度慢频SLOW稳走模式;缩减腿部hip/knee/ankle步态输出缩放系数,减小实际步高步距;降低CPG耦合强度,左右腿动作过渡更平滑无冲击,如图5所示:
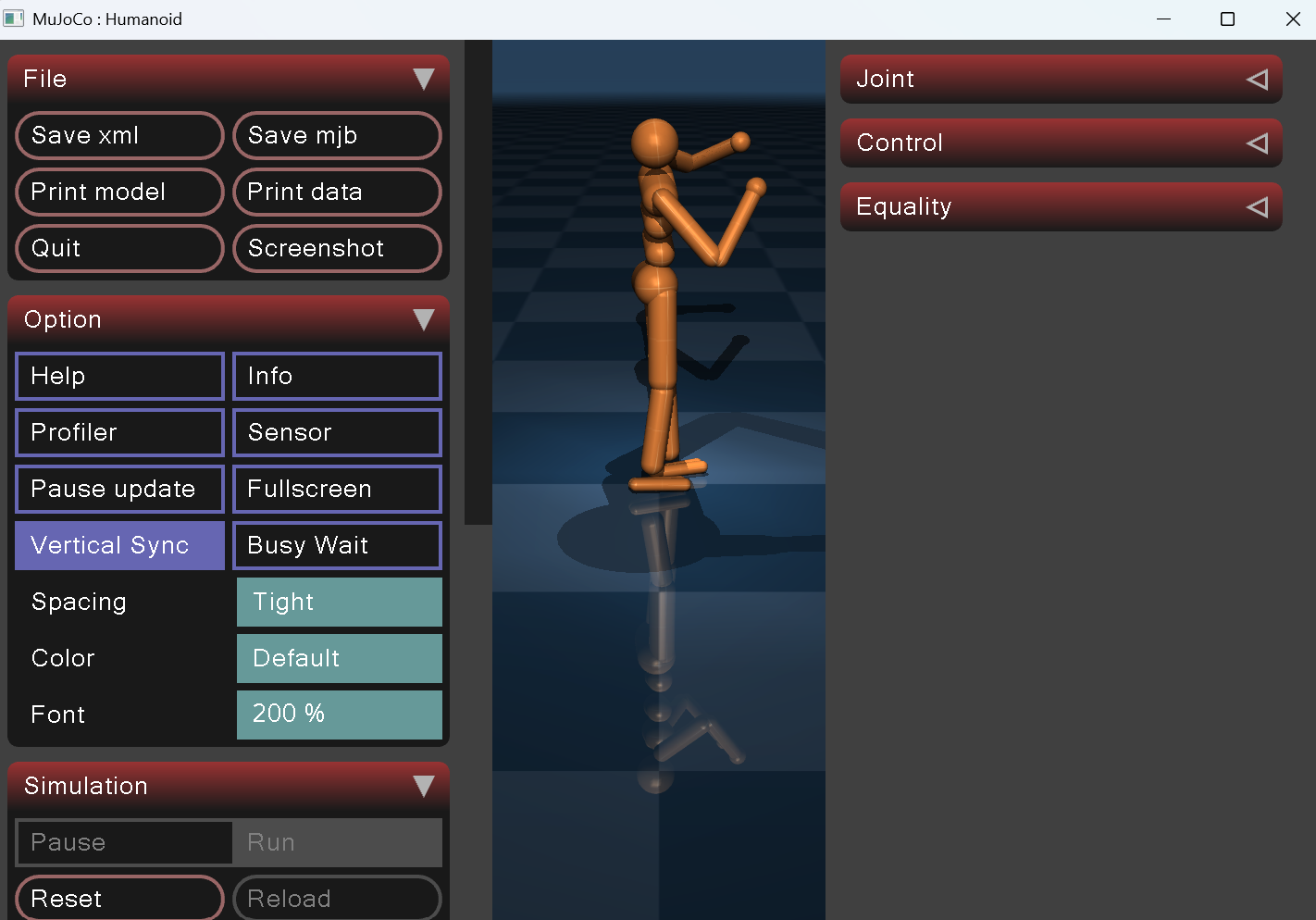
图5 调整后步态平稳、晃动减小
6.4 难点4:站立不稳
问题:仿真重置后关节目标值过渡生硬,7秒预稳定阶段手臂、躯干瞬间出现抬臂弯折姿态,启动阶段就姿态崩坏,无法站立稳定,如图6所示:
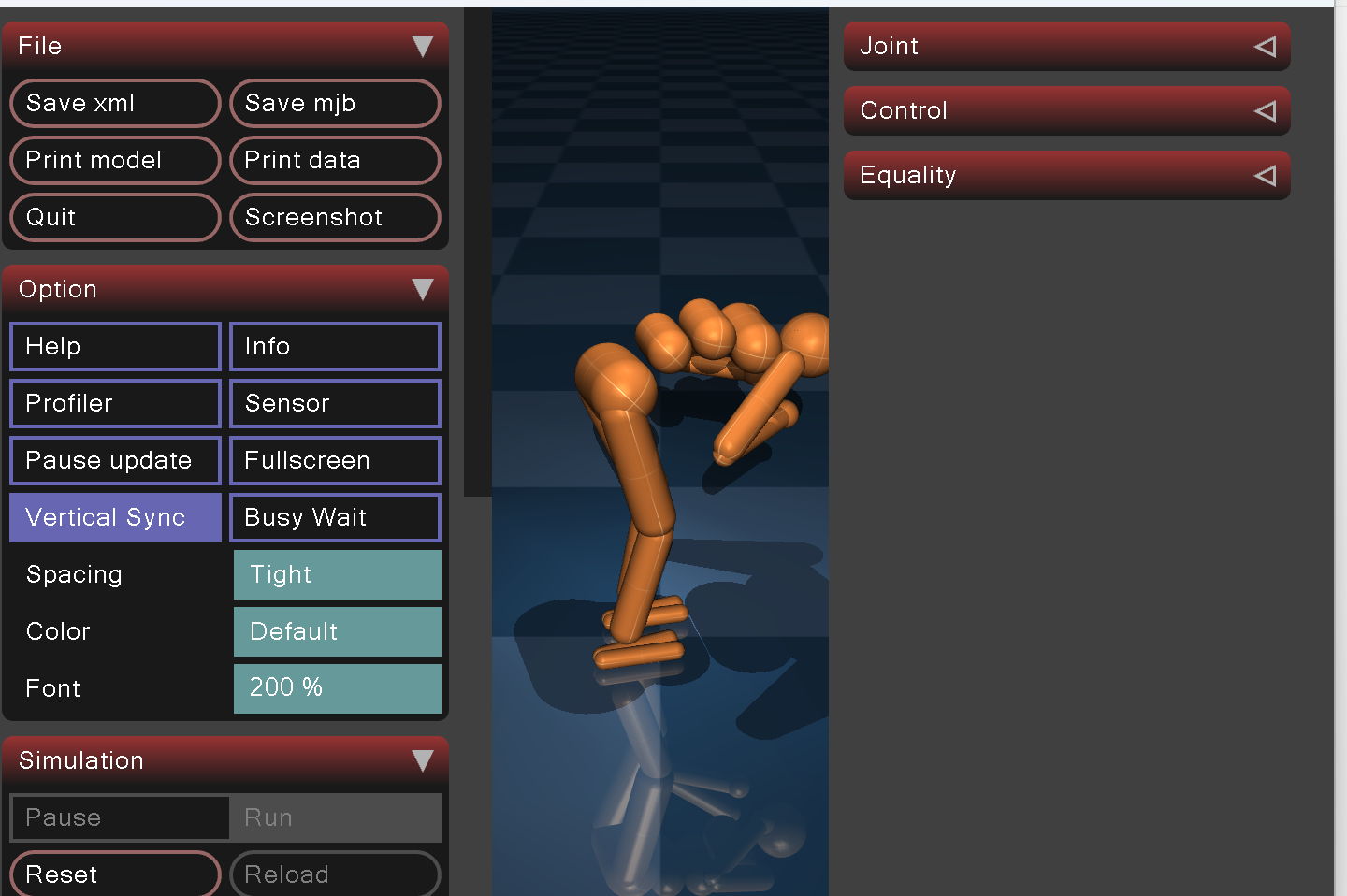
图6 启动阶段抬臂弯折、站立不稳
原因:仿真初始化时,MuJoCo 模型刚加载,关节位置和速度均为零或默认值,而 CPG 控制器和姿态控制器尚未建立有效的反馈。如果直接以满力矩启动,关节目标值的阶跃变化会导致执行器瞬间输出较大力矩,手臂和躯干在重力作用下产生惯性冲击,出现抬臂、弯腰等畸形姿态。同时,CPG 振荡器初始相位随机或未复位,左右腿目标不一致,进一步加剧了启动初期的不稳定。
解决:复位函数固化竖直垂臂标准零偏移初始位姿;预稳定阶段力矩随时间线性缓升,禁止瞬间满力矩冲击;站立状态强制重置 CPG 振荡器、清零上身偏移量,可以保持7秒稳定,如图7所示:
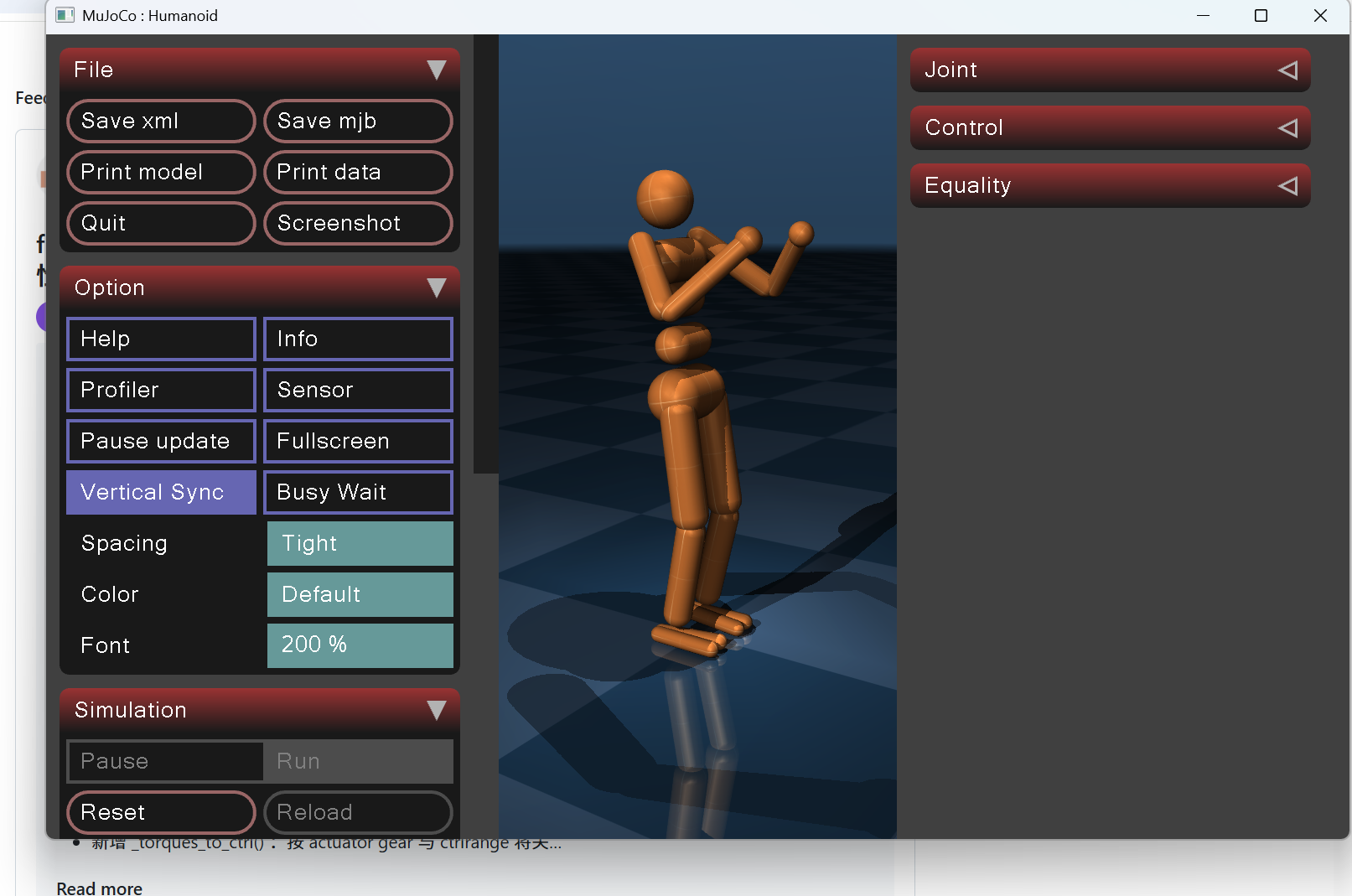
图7 力矩缓升后稳定站立
7. 运行说明与效果展示
7.1 键盘控制指令
| 按键 | 功能 |
|---|---|
| W | 缓步前进 |
| X | 缓步后退 |
| A / D | 左右转向 |
| S | 停止行走、直立站立 |
| 空格 | 方向回正 |
| 1 / 2 / 3 / 4 | 切换慢走/正常/小跑/原地踏步步态 |
| P | 加载 SAC 强化学习优化步态 |
| R | 整机复位、恢复标准站姿 |
7.2 运行效果
- 稳定初始站立,无抖动、无倾倒
- 四模式步态平滑切换,行走自然仿生
- 支持前后行走、左右转向、平滑启停
- SAC 模型加载后步态更平顺、抗扰动更强
- 接收 ROS 远程指令,可适配机器人自动驾驶系统
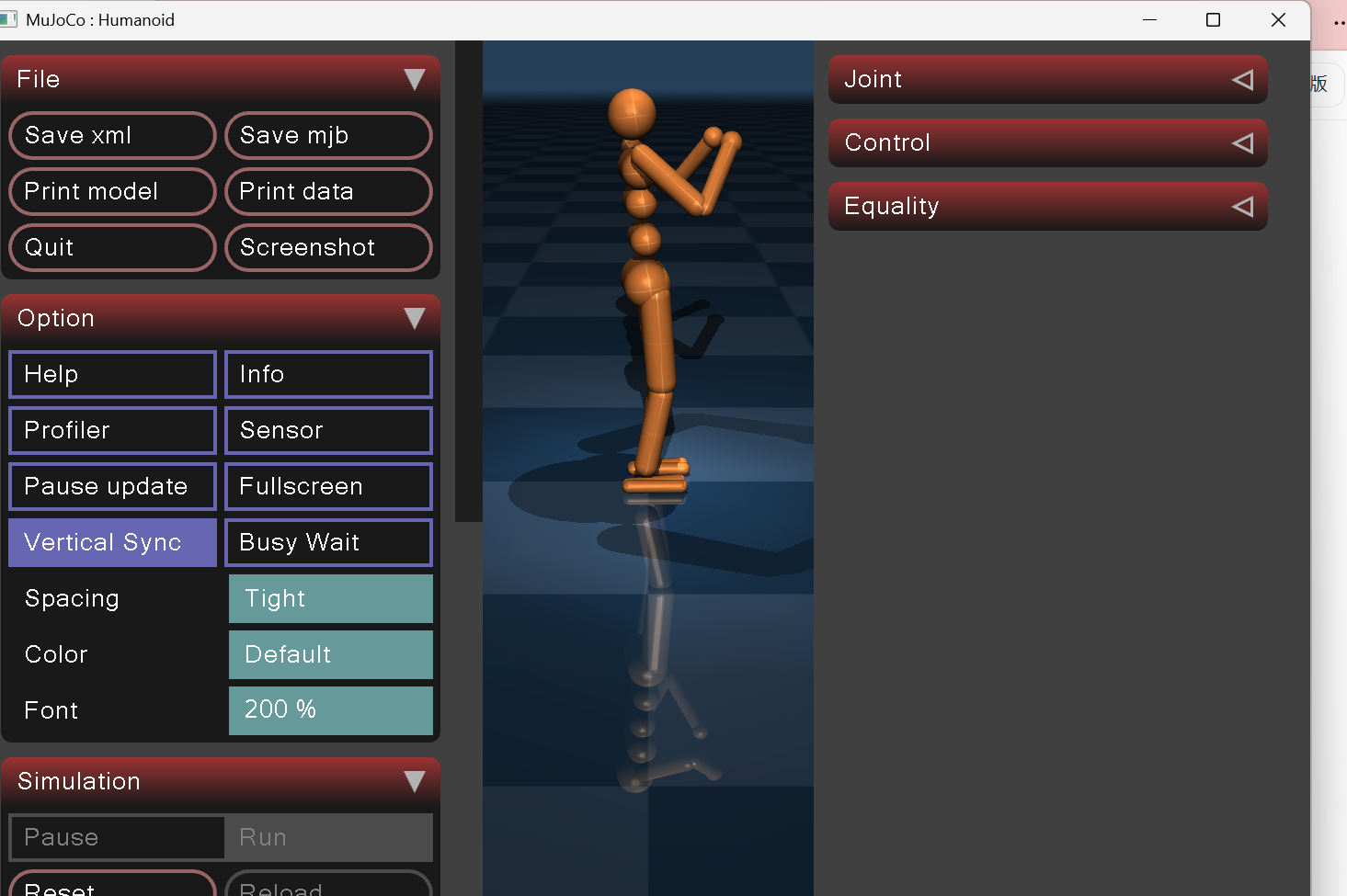
8. 现存不足与后续优化方向
8.1 现存不足
目前系统虽然实现了稳定的平面行走和基础的强化学习优化,但仍存在一些不足。基础 CPG 步态的核心参数(如频率、振幅、耦合强度)仍然依赖人工手动调节,智能化上限有限,难以自动适应更复杂的行走需求。系统目前仅适用于平面行走,缺乏对斜坡、台阶等复杂地形的适配策略。此外,控制框架中没有加入 ZMP(零力矩点)约束,极限稳定性方面还有提升空间。最后,机器人跌倒后仅支持复位保护,没有主动的跌倒恢复动作。
8.2 后续优化方向
针对上述不足,后续可以从以下几个方面进行优化。在深度强化学习方面,可以对比 PPO、TD3 等不同算法的效果,进一步优化奖励函数,提升高速行走的稳定性。在地形适应性方面,增加斜坡、台阶、颠簸地面的域随机化训练,提升机器人在复杂环境中的行走能力。在平衡控制方面,加入 ZMP 约束,优化重心轨迹规划,拓宽稳定边界。在故障恢复方面,设计起身动作序列或训练跌倒恢复策略,实现全自动故障恢复。此外,还可以进行完整的 Sim2Real 迁移工作,通过引入噪声、通信延迟和参数扰动,使策略能够平滑迁移到真实机器人;以及接入视觉观测,实现自适应避障和路径跟随行走。
9. 项目总结
本项目建设了一套基于 CPG 仿生步态、自适应 PD/PID 稳定控制和 SAC 残差强化学习的分层人形机器人控制系统。相比纯规则控制方法,本系统引入了强化学习残差微调,提升了步态的自然度和适应性;相比纯强化学习方法,底层规则控制器提供了稳定性兜底,避免了训练过程中的频繁崩溃。通过一系列工程优化,解决了 MuJoCo 仿真中常见的关节索引错位、控制指令无效、开局摔倒和步态抖动等问题,最终实现了稳定站立、多模式行走、实时交互和 AI 步态优化的完整闭环。
本系统同时具备工程应用价值和算法研究价值,既可以作为人形机器人运动控制的一个稳定基线,也可以用于残差强化学习、Sim2Real 迁移等方向的算法实验。希望这个项目课可以给你带来一点思考和研究价值。
参考文献
[1] 林宇舜,李杰,陈之焕,等. 结合评价模型与多Q值SAC的交叉口信号控制方法[J/OL].福州大学学报(自然科学版),1-8[2026-06-12].https://link.cnki.net/urlid/35.1337.N.20260511.1404.004. [2] 钱姜枚,李唯唯. SCMRec:基于SAC与对比学习的多模态推荐[J/OL].软件导刊,1-8[2026-06-12].https://link.cnki.net/urlid/42.1671.TP.20260414.1404.027. [3] 周晓光,张源原,徐光达,等. 基于RRT-SAC算法的无人机路径规划方法[J].火力与指挥控制,2026,51(4):121-129. [4] 袁雯. 基于改进的DDPG的仿人机器人运动实验[J].中国新通信,2026,28(1):4-6. [5] 刘虎. 基于图像特征与残差神经网络的配电网电缆缺陷识别与定位研究[D].西安理工大学,2025.DOI:10.27398/d.cnki.gxalu.2025.001406.